2025-04-29
Feature Overview
| Feature | Free | 1 Yuan Trial | Personal | Enterprise |
|---|---|---|---|---|
| Short Link | ✅ | ✅ | ✅ | ✅ |
| Dynamic QR Code | ✅ | ✅ | ✅ | ✅ |
| Click Analytics | ✅ | ✅ | ✅ | ✅ |
| Bot Filtering | ✅ | ✅ | ✅ | ✅ |
| WeChat Access | ❌ | Valid 10 days | ✅ | ✅ |
| Analytics Dashboard | ❌ | ❌ | ✅ | ✅ |
| Access Password | ❌ | ❌ | ✅ | ✅ |
| Real-time Editing | ❌ | ❌ | ✅ | ✅ |
| Custom Domain | ❌ | ❌ | ❌ | ✅ |
| Bulk Creation | ❌ | ❌ | ❌ | ✅ |
| Phone Number Collection | ❌ | ❌ | ❌ | ✅ |
| WeChat User Info Collection | ❌ | ❌ | ❌ | ✅ |
| Custom Development | ❌ | ❌ | ❌ | ✅ |
Short Link Algorithm
The short link code (referred to as code) is mapped one-to-one from the primary key (referred to as pk) in the database. This mapping process uses the FF3-1 Format-Preserving Encryption algorithm.
- Why not use the Snowflake algorithm?
- Our short link code is only 6 characters long. If we use the Snowflake algorithm, 8 bytes of data will be base62 encoded to 11 characters, which does not meet our requirements.
- Last year, the total number of marketing SMS messages was around 10 billion, with about 6 billion of them using short links. SMS charges are based on the number of characters (every 70 characters counts as one unit).
- A 6-character short link corresponds to an int type size of 5 bytes. For a 5-byte Snowflake ID, it is more efficient to use the sequenceID directly, which is the database PK.
- Why not encrypt the PK directly to generate the code?
- The PK is of int64 type, and encrypting it to generate a code would result in an 11-character string, incurring additional costs.
System Design
The process of creating a short link is as follows:
ID Generator
When creating a short link, the ID generator provides a unique and continuous database pk for the "Create Short Link" API.
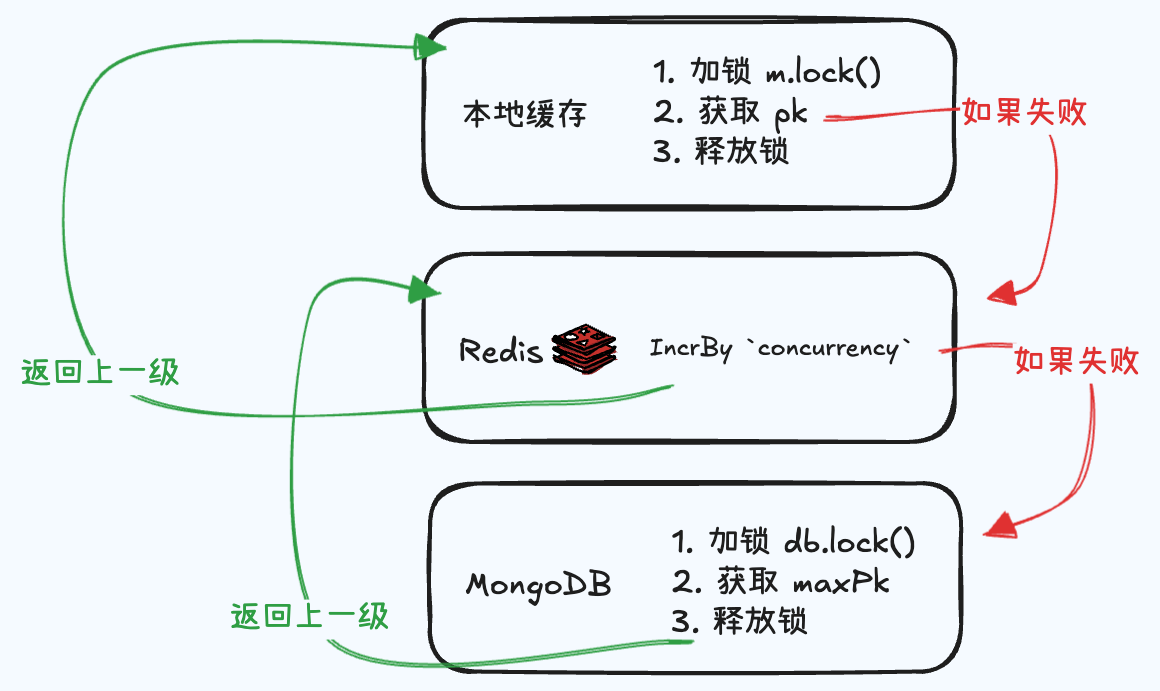
As shown in the figure above:
- When the
getPk()function is called, it first attempts to retrieve the pk from the local cache. - If the pk range exceeds
maxPk, it will batch retrieve pk from Redis usingincrBy xxx 'concurrency'and update the local cache. - If the pk in Redis has expired, it will execute
SELECT MAX(pk)from the database,
Limitations of the above process:
- When the local pk is exhausted, there will be a wait for the result from Redis.
- When the Redis key expires, there will be a wait for the result from the database.
Optimization Suggestions:
- Proactively fetch new Redis pk concurrently when
Remaining local cached Pk < Current concurrency - Redis should use automatic key expiration renewal:
Redis Pk = Max(maxRedisPk, maxDBPk)
Why no optimization currently?
- According to pprof analysis, the most time-consuming operations are DB Insertion and RabbitMQ Statistics. The time spent on Redis pk retrieval is already negligible.
- After implementing "DB Batch Insert" in the next section, the largest performance bottleneck will be on RabbitMQ Statistics.
DB Batch Insert
The "DB Batch Insert" process is used to batch multiple insert operations into a single database operation when creating a short link. This reduces the pressure on the database and allows for simultaneous return of the insertion results. The idea is to cache the ongoing insert operations and trigger a goroutine for batch insertion every 50ms.
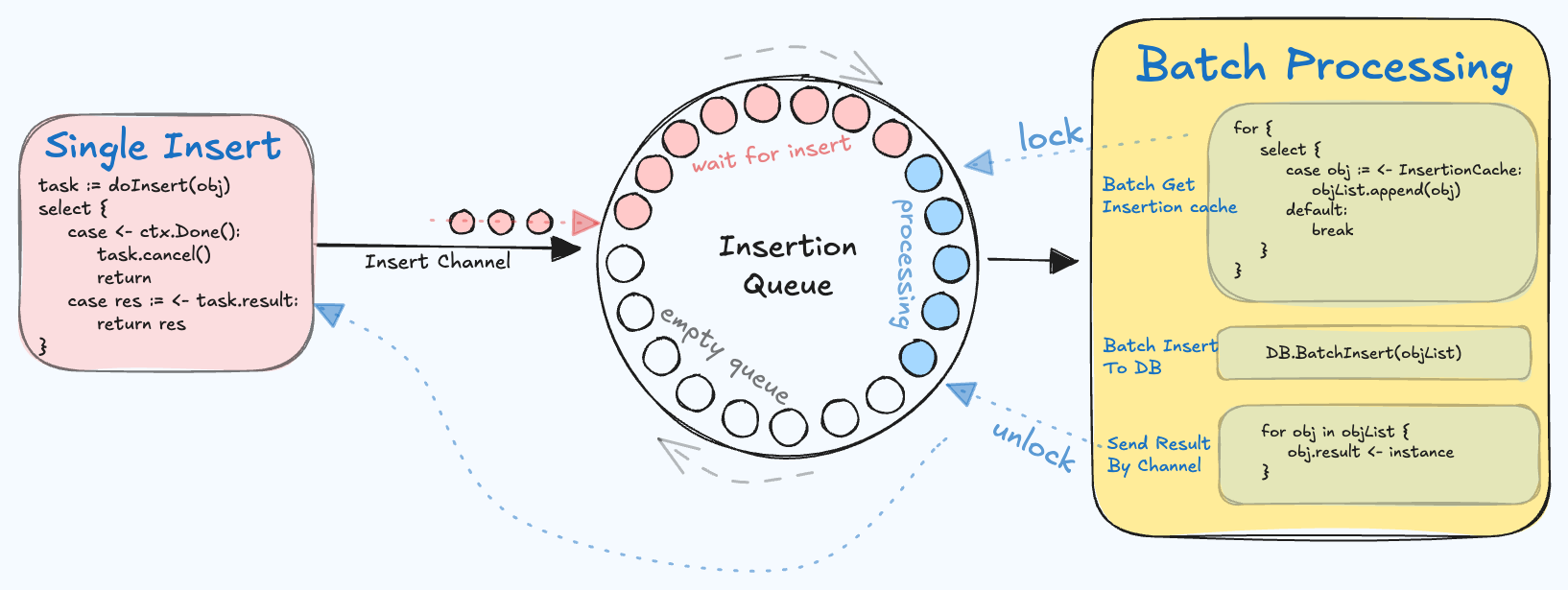
As illustrated, each obj in the queue has a mutex lock and a channel object. The goroutine on the left acquires the lock before the batch insert operation begins and releases it after the operation ends, sending the result to the goroutine on the right through the channel.
The atomic.CompareAndSwap function is used to ensure that only one goroutine is performing the batch insert at any given time.
func singleInsert() {
...
// Only prepare a new goroutine if none is pending
if atomic.CompareAndSwap(&BatchInsertPreparingFlag, 0, 1) {
go time.AfterFunc(50ms, batchInsert)
}
...
}
func batchInsert() {
// Allow preparation of the next BatchInsert operation
isPrepared := atomic.CompareAndSwapInt32(&BatchInsertPreparingFlag, 1, 0)
// Ensure only one BatchInsert is running at the same time
if !atomic.CompareAndSwapInt32(&BatchInsertRunningFlag, 0, 1) {
if isPrepared {
isPrepared = atomic.CompareAndSwapInt32(&slBatchInsertPreparingFlag, 0, 1)
if isPrepared {
go time.AfterFunc(slTimeout, this.doCreate)
}
}
return
}
defer func() {
if !atomic.CompareAndSwapInt32(&BatchInsertRunningFlag, 1, 0) {
panic(fmt.Errorf("short link manager unexpected 0")) // Should not reach here
}
}()
...
}
By adding the Prepare goroutine method, we can avoid the situation where some SingleInsert operations are not executed due to race conditions. This can be proven by contradiction.
Race Condition 1:
When A is being inserted and go BatchInsert is called, B does not call go BatchInsert, and the data from does not include B's data. As a result, B is never inserted.
Conditions for occurrence:
has started but is not yet running. B reaches atomic.CompareAndSwap(&BatchInsertPreparingFlag, 0, 1) and finds that a goroutine is already in preparation, so it skips the operation.
starts running normally and gets A's data, but not B's data.
However, since the B enqueue operation is before the atomic.CompareAndSwap(&BatchInsertPreparingFlag, 0, 1) check, B's data must have been enqueued at this point and can be successfully detected.
Proof complete.
Race Condition 2:
When A is being inserted and go BatchInsert is called, B also calls go BatchInsert. However, if times out while the coroutine is still stuck at the DB insertion step, will fail to acquire the lock and exit directly, causing B to never be inserted.
Solution: When is running, check if there is an ongoing operation. If there is, re-prepare the goroutine.
The final effect is that during high load, there is always a Prepare goroutine waiting to execute. During low load, no extra executions will occur.
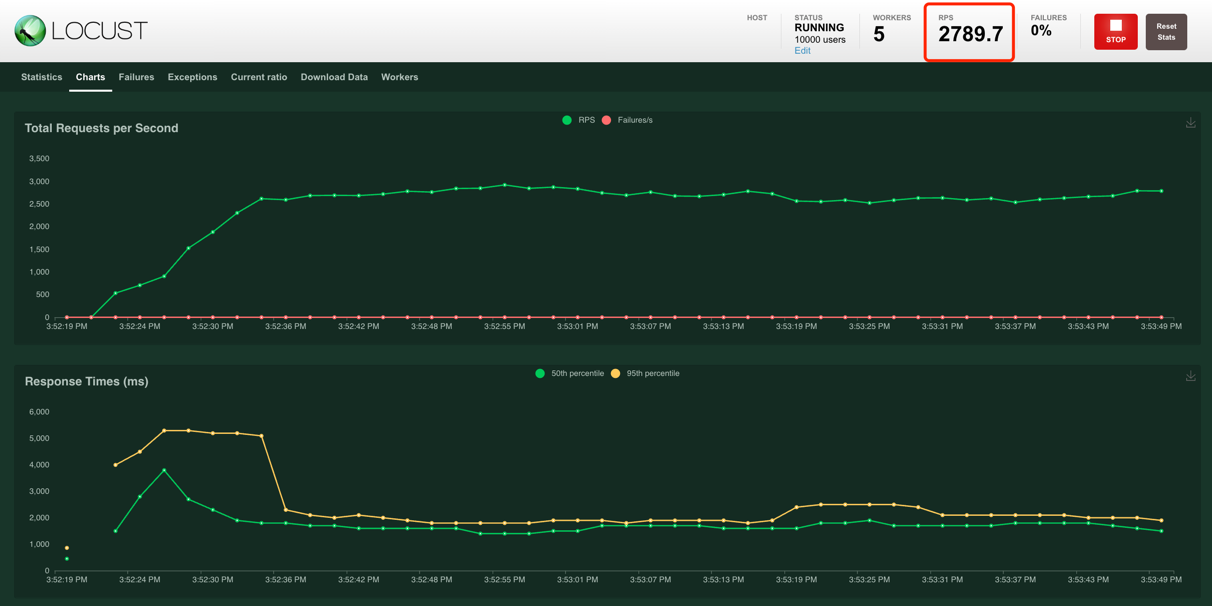
Load Testing
- Machine: Mac Book Pro M1 (2020)
- Database: MongoDB
Supports over 2500 concurrent creations per second.
Supports over 4000 concurrent accesses per second.
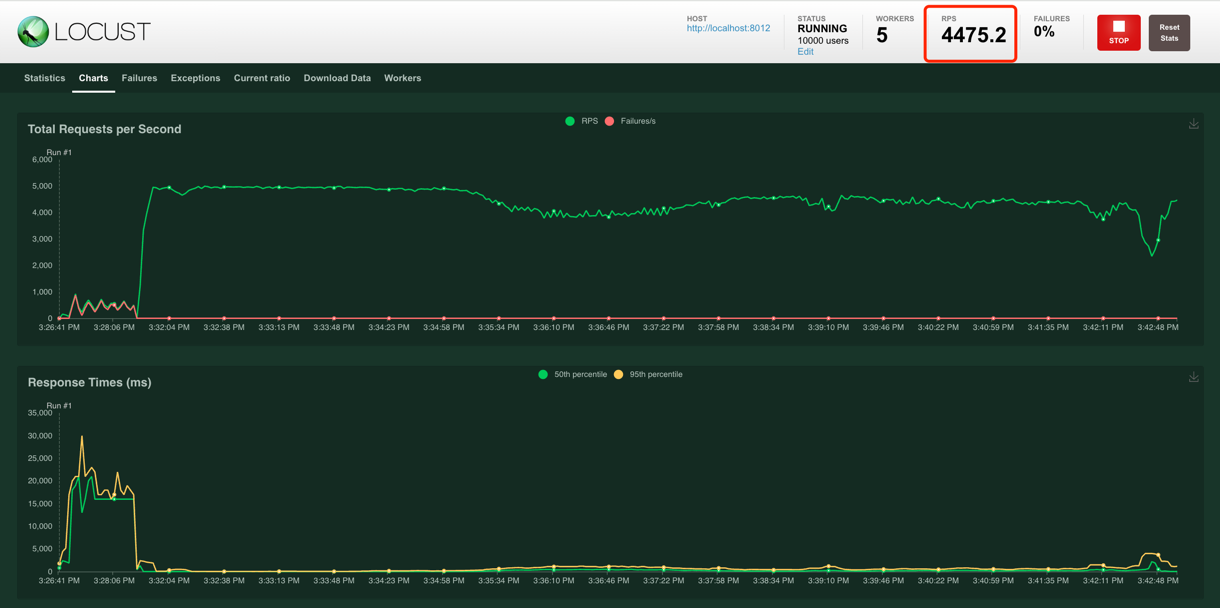
For example, click knowuv.com/mgex8 to visit the short link.
Technical Support
- You can directly email dusty-cjh@qq.com