2025-04-29
功能说明
| 功能 | 免费版 | 1 元试用 | 个人版 | 企业版 |
|---|---|---|---|---|
| 短链 | ✅ | ✅ | ✅ | ✅ |
| 活码 | ✅ | ✅ | ✅ | ✅ |
| 访问统计 | ✅ | ✅ | ✅ | ✅ |
| 过滤爬虫 | ✅ | ✅ | ✅ | ✅ |
| 微信访问 | ❌ | 10 天内有效 | ✅ | ✅ |
| 数据看板 | ❌ | ❌ | ✅ | ✅ |
| 访问密码 | ❌ | ❌ | ✅ | ✅ |
| 实时修改 | ❌ | ❌ | ✅ | ✅ |
| 导出数据 | ❌ | ❌ | ✅ | ✅ |
| 自定义域名 | ❌ | ❌ | ❌ | ✅ |
| A / B 测试 | ❌ | ❌ | ❌ | ✅ |
| 批量创建 | ❌ | ❌ | ❌ | ✅ |
| 收集手机号 | ❌ | ❌ | ❌ | ✅ |
| 填写表单后访问 | ❌ | ❌ | ❌ | ✅ |
| 地域限制 | ❌ | ❌ | ❌ | ✅ |
| 引导浏览器打开 | ❌ | ❌ | ❌ | ✅ |
| 定制开发 | ❌ | ❌ | ❌ | ✅ |
短链算法
使用数据库主键(pk)一一映射到短链码(code),这个映射的过程使用的是FF3-1 保形加密算法。
Golang 加密算法开源:https://github.com/dusty-cjh/golang-fpe
- 为什么不使用雪花算法?
- 我们的短链长度只有 6 位,如果使用雪花算法,8 字节的数据 base62 编码后会达到 11 位,不符合要求。
- 去年全年的营销短信数量在 100 亿左右,其中用到短链的有 60 亿,而短信是以字数(每70字)计费的。
- 6 位短链对应的 int 类型大小为 5 字节,对于 5 字节的雪花算法来说,不如直接用 sequenceID,即数据库 PK。
- 为什么不直接用 PK 加密成 code?
- PK 是 int64 类型,加密成 code 以后会变成 11 位的字符串,带来额外成本。
系统设计
一定要先确定好需求,这里的目的是打造低成本、单机万级并发的短链系统。
创建短链的流程是这样的:
发号器
在创建短链时,发号器用来给 “创建短链” API 提供唯一的、连续的数据库 pk。
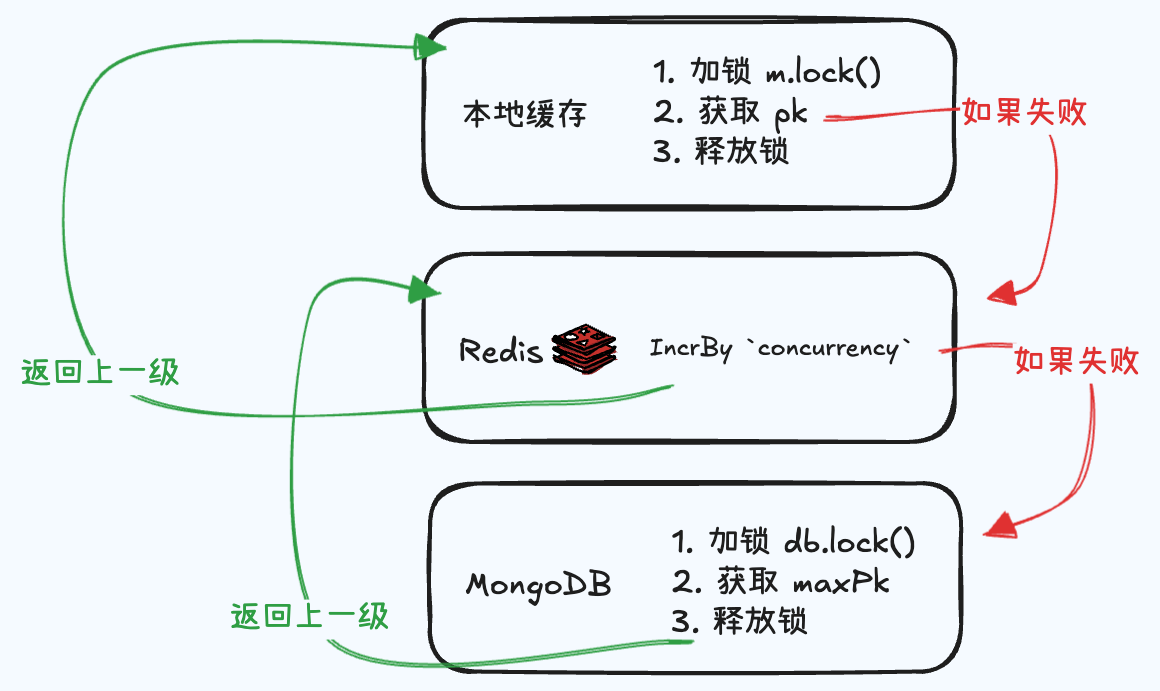
如上图所示:
- 调用
getPk()函数时,会先从本地缓存中获取 pk, - 如果 pk 的范围超出
maxPk,则会从 redis 中incrBy xxx 'concurrency'批量获取 pk,更新到本地缓存中。 - 如果 redis 中的 pk 过期,则会从数据库中
SELECT MAX(pk),
上图流程中的不足:
- 当本地 pk 耗尽时,需要等待从 Redis 获取 pk 的结果
- 当 Redis Key 过期时,需要等待从 DB 获取 pk 的结果
优化建议:
- 当
剩余本地缓存Pk量 < 当前并发量时,主动并发拉取新的 Redis Pk - Redis 使用自动续期:
Redis Pk = Max(maxRedisPk, maxDBPk)
为什么当前不优化?
- 根据 pprof 分析,最大的耗时在DB 插入 和 RabbitMQ 统计数据 上,而 Redis 获取 pk 这部分的占比已经可以忽略不计了。
- 在下一节实现 “DB 批量插入” 后,最大的性能损失就只在 RabbitMQ 统计数据 上了。
DB 批量插入
在创建短链时,”DB批量插入“ 用来把单个创建批量化,减少数据库压力,同时能同步返回插入结果。思路就是缓存正在进行的插入操作,每间隔 50ms 启动用于批量插入的 goroutine 一次。
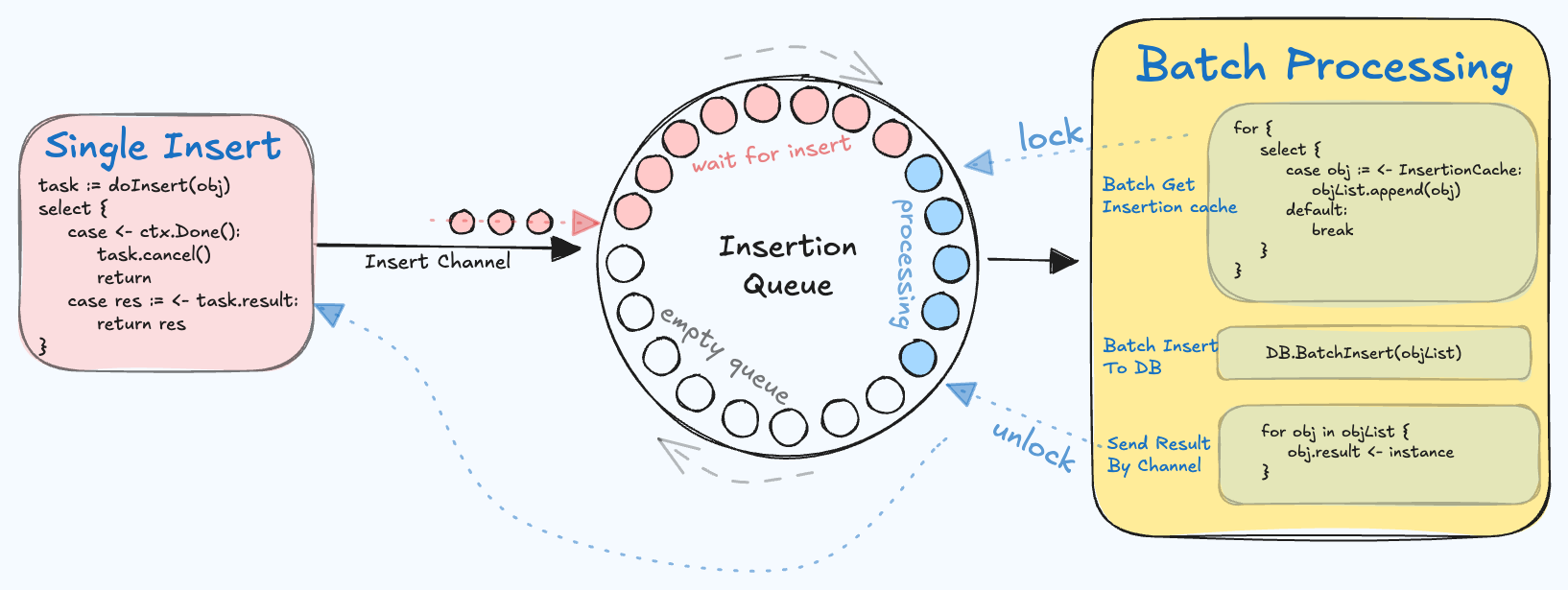
如图所示,每个队列中的 obj 都有一个 mutex 锁和 ch 对象。左边的 goroutine 会在批量插入操作开始前获取锁,批量插入操作结束后释放锁,
并将结果通过 ch 发送到右边的 goroutine。
可以使用 atomic.CompareAndSwap 函数保证同一时间只有一个批量插入的 goroutine 在运行。
func singleInsert() {
...
// 仅当没有预备中的 goroutine 时,预备新的 gouroutine
if atomic.CompareAndSwap(&BatchInsertPreparingFlag, 0, 1) {
go time.AfterFunc(50ms, batchInsert)
}
...
}
func batchInsert() {
// 允许预备下一个 BatchInsert 操作
isPrepared := atomic.CompareAndSwapInt32(&BatchInsertPreparingFlag, 1, 0)
// 确保同一时刻只有一个 BatchInsert 正在运行
if !atomic.CompareAndSwapInt32(&BatchInsertRunningFlag, 0, 1) {
if isPrepared {
isPrepared = atomic.CompareAndSwapInt32(&slBatchInsertPreparingFlag, 0, 1)
if isPrepared {
go time.AfterFunc(slTimeout, this.doCreate)
}
}
return
}
defer func() {
if !atomic.CompareAndSwapInt32(&BatchInsertRunningFlag, 1, 0) {
panic(fmt.Errorf("short link manager unexpected 0")) // 不可能触达
}
}()
...
}
通过添加 Prepare goroutine 的方法,可以避免因为竞态问题导致部分 SingleInsert 没被执行到。可以用反证法来证明这一点。
竞态问题 1:
当 A 插入并且 go BatchInsert 时,B 未 go BatchInsert,且 并未获取到 B 的数据。导致 B 永远不会被插入。
发生条件:
已启动未运行,B 走到了 atomic.CompareAndSwap(&BatchInsertPreparingFlag, 0, 1),发现已有在预备的 goroutine,遂跳过。
开始正常运行,获取到 A,但未获取到 B 的数据。
但由于B 入队列操作在 atomic.CompareAndSwap(&BatchInsertPreparingFlag, 0, 1) 检查之前,所以此时 B 数据必然已入队列,可被成功发现。
证明完毕
竞态问题 2:
当 A 插入并且 go BatchInsert 时,B 也 go BatchInsert,但直到 协程超时, 依然卡在插入DB这一步上,导致 取锁失败直接退出,B永远不会被插入。
解决方案: 当 运行时,探测是否有正在运行的 操作,如果有,则重新 Prepare goroutine。
最终的效果就是,当高负载时,总有一个 Prepare goroutine 在等待执行。当低负载时,不会有任何额外的 执行。
审核
以下情况会触发审核:
- 创建
- log2(访问量) 为整数
- 更新后有新访问量
审核机制:
- 使用 playwright-mcp 获取:网页语义描述、网页首屏截图
- LLM 输入 截屏 / 页面标题 / 页面描述,输出 0-1 之间的 spam 分值,以及判分理由
- 超出阈值则封禁链接
系统设计:
远端使用 Redis ZSet 存储需要审核的链接,根据时间戳排序。本地使用 CronJob 定时从 ZSet 拉取数据审核。
弊端:
源链接通过判断 User-Agent / 是否移动设备 / 是否微信环境 / 访问者所处IP城市 来决定自己展示什么内容,防不胜防。 AI 审核机制只能过滤基础的垃圾链接,一旦链接通过技术手段伪装自己,将很难被识别。
性能:
- playwright-mcp 部署在自己的服务器上
- LLM 用的七牛云部署的 Doubao 1.6 Pro
- 审核队列用的 Celery 定时任务,每分钟执行一次,带缓存锁,每次执行耗尽审核队列,或超时 10 分钟后退出。
白名单、黑名单秒过。
普通链接 1 分钟每条,速度较慢,不过目前符合需求。
防篡改
模版落地页的 url query 中会放用户自定义的数据,然后渲染。
但是攻击者会写入恶意内容来篡改数据,展示违规未审核的页面。如何解决?
方案是加签名✍️:
- 使用基于 Zero Knowledge Proof 的签名算法,对时间戳加签名。
目前仅对时间戳加签名,这能防止别人随意修改内容。
但是如果有人不停获取时间戳然后替换的话,还是危险。
但是已经提升了篡改的门槛,使篡改的成本大于篡改得到的收益,那就能够杜绝篡改。
数据统计
效果:
- 系统面板展示今日、过去 2 周创建、访问量
- 用户面板展示今日、过去 2 周创建、访问量
- 单个短链可展示小时级的访问曲线
实现:
当用户访问短链时会触发 RabbitMQ 消息,数据统计操作在消息队列中发生。
消息体结构:
// MsgAppPv 表示短链访问统计的消息体结构。
type MsgAppPv struct {
Date string // 访问日期(如 "2024-06-25")
Url string // 访问的短链 URL
ClientUid string // 客户端唯一标识(回溯)
PK int // 短链主键
UserAgent string // 客户端 User-Agent
IP string // 访问者 IP 地址
Referrer string // 来源页面 URL
RequestedWith string // 请求来源(判断源站,提供完整访问上下文信息)
ShortLinkOwner int64 // 短链所有者用户ID
}
当日访问数据保存在 Redis,次日通过异步任务存入 DB。
主要保存的数据:
- 系统
- 每日访问量
- 短链
- 链接ID + 用户ID 的日访问量
- 链接ID 的小时访问量
- 全量的访问详情
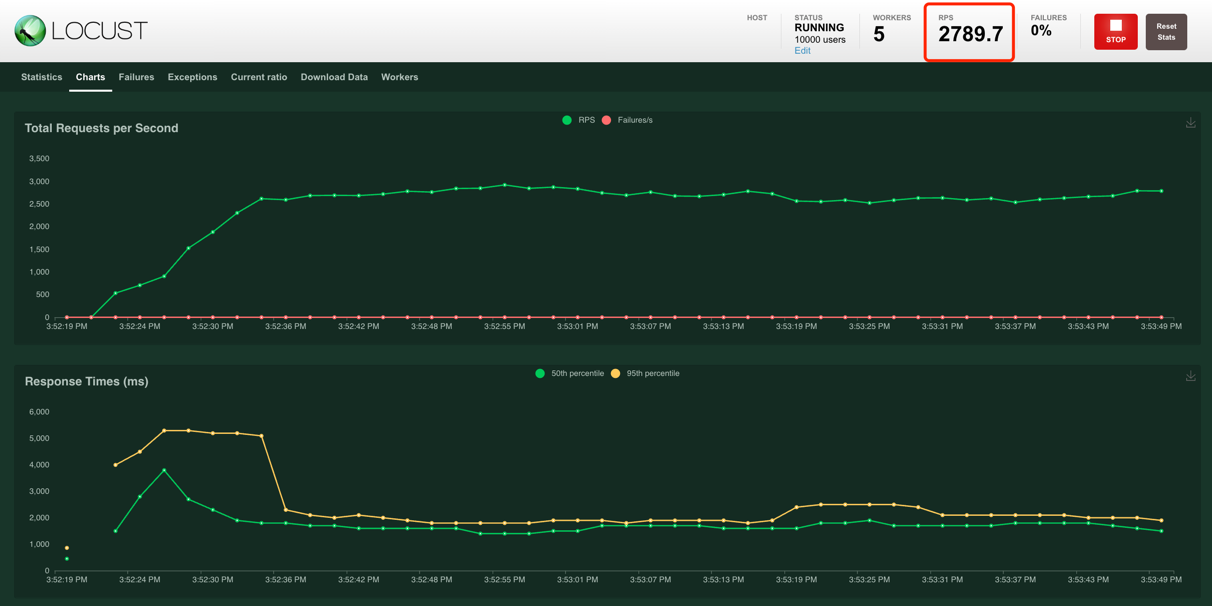
压力测试
- 机器:Mac Book Pro M1 (2020款)
- 数据库:MongoDB
支持每秒 2500+ 同时创建。
支持每秒 4000+ 同时访问。
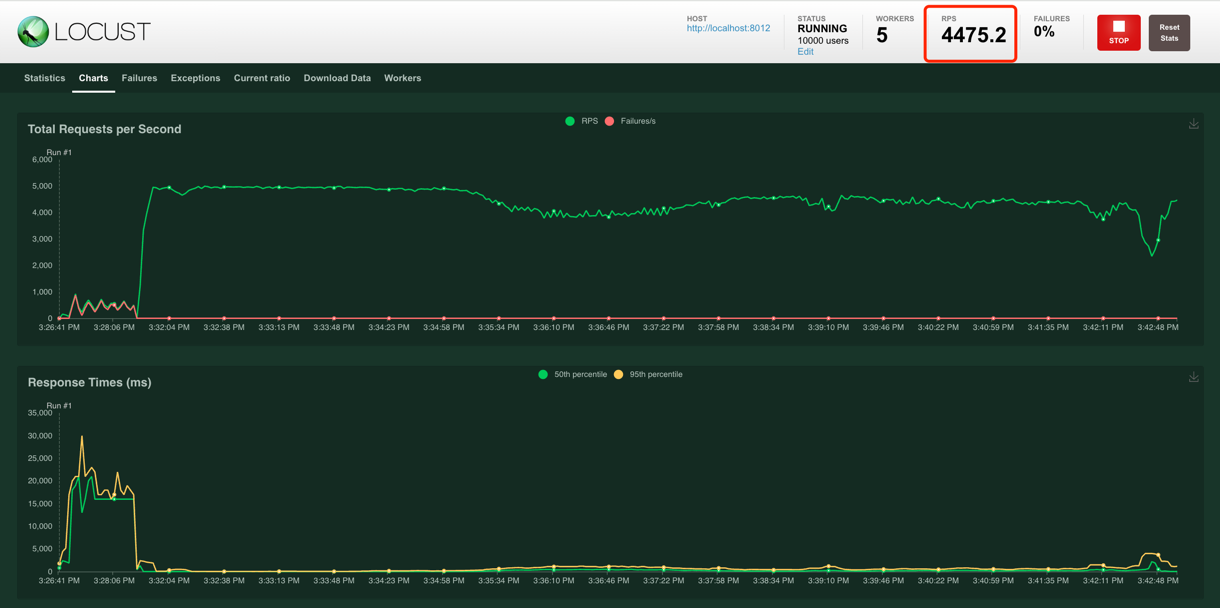
例如,点击 knowuv.com/sl/F9GA9 访问短链。
监控体系
使用 Prometheus + Grafana 监控系统的关键指标。
Api Token 权限设计
- 背景
纷玩岛抢票时,有同行 DDOS 攻击,导致服务器压力山大。
- 目的
- 能快速拦截非法流量
- 能快速判断用户权限(比如是否有操作某 API 的权限)
- 短、快
- 格式
{userId}{timestamp}{ApiPrivilegeBloomFilter}
int64 + int64 + bytes[16]
其中:
ApiPrivilegeBloomFilter是该 Token 所拥有的 API 权限合集的 bloomFilter 值。
最终的 Token 格式:token = Base64(AES(raw))
当访问 rpc 接口时,通过 userId 范围 + timestamp 范围 + bloomFilter 可以直接过滤 99.99% 非法流量。
然后再通过该 Token 查 DB 获取 具体 Token 详情二次校验(此处已经基本很少流量)
- 缺陷:对方如果 Copy 了合法请求,那么流量依然会来到后端
- 不过这种请求是收费的,他愿意也可以
但这里有个问题:用户生成链接后,同行拿到这个链接,滥用其中的 Token,导致用户资产损失。
所以我在想,是否应该在 token 中加入 checksum,确保该 Token 仅对特定参数的用户链接有效。
但是另一方面, Token 模块应该是一个全局共用的机制,如果单纯为了这一个“用户生成链接”的需求而修改整体 Token 模块的设计,违反了 SOLID 原则,得不偿失。
如何二者兼顾?
这是一个伪需求。 Token 负责鉴权,checkSum(更官方叫 fingerprint)添加到请求参数中。
只有后台生成的参数才可以通过 checkSum 校验,此时攻击者就无法生成违规请求了。
- 性能优化
对于 bloomFilter,用 hash/maphash 直接自己实现一个,很简单,没必要用库。
连续 hash 两次,刚好能生成 16 字节的 AES 加密块。
当使用多个 cipher block 的 AES 加密时,必须使用非 ECB 模式。
我这里可以使用:
- 第一个块,是 userid + expireTime, ECB 加密
- 第二个块,是 bloomFilter, 用 CBC + 第一个块作为 iv 加密
外部小程序跳转链接设计
参考:
有两类跳转方式:
- 外部跳转微信小程序
- 外部跳转微信二维码
- 个人二维码
- 企业微信群二维码
- 企业微信个人二维码
外部跳转微信小程序
小程序通过 URL query code 获取跳转信息。
这个 API 不需要登录,所以要考虑 DDOS 攻击。
message GetMpJumpInfoRequest {
string code = 1;
}
message GetMpJumpInfoResponse {
string appId = 1; // Target mini program appId
string name = 2; // Display name
string icon = 3; // Icon URL (optional)
string path = 4; // Target page path (optional)
string description = 5; // Description text (optional)
string envVersion = 6; // "release" | "trial" | "develop"
int32 code = 7;
string msg = 8;
}
- 生成过程
- 需要提前获取对应的 code 换取
URL Scheme - 然后根据
URL Scheme生成短链
- 需要提前获取对应的 code 换取
这里有个先有鸡还是先有蛋的问题,生成短链 URLScheme 需要 pk,但是 pk 需要生成短链后才能获取。
解决方案:
- 直接在 CreateShortLInk Request 里加 pk 字段, manager 层暴露 NewPkV2 让上层调用。
这里会引入新的问题:
- pk 不能随便改,如何识别该 pk 是系统生成而非用户生成的 pk 呢?
答案是用下面三个 header:
// sign
RequestTsHeader = "X-Request-Timestamp"
RequestNonceStr = "X-Request-Nonce"
RequestSignature = "X-Request-Signature"
其中:
这样的话,只有通过该校验的 pk 才会被使用,否则 request 会直接被拒绝。
其次,这个机制也是全局可复用的。
更好的方式是用真正的 HMAC,即整体 request BODY 校验,但没必要。
证书问题
- 小程序、微信、系统,这三个对证书的要求不一样,我淘宝买的证书有的时候不能用。
解决方案:
- Traefik 申请 LetsEncrypt 证书
- Celery Task 周期同步 LetsEncrypt 证书到阿里云 SLB
- 这里的证书是用 API
docker cp traefik:/ssl-certs/acme.json /tmp/acme.json
技术支持
- 您可直接发送邮件到 dusty-cjh@qq.com